
DynamoDB Auto Scalingのキャパシティー数減少に失敗していた(`Failed to set write capacity units to X`)
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
コンサル部の神野です。
DynamoDB Auto Scalingの失敗時にエラー(Failed to set write capacity units to X)が発生していて、何が原因だろうと思い調査していました。
調査した結果や考えを踏まえてAuto Scaling失敗時の対応方法検討について説明していきたいと思います。
前提・発生したエラー
対象テーブルの前提
- キャパシティモード:
プロビジョンド - Auto Scaling :
ON(読み取り・書き込み)- 最小キャパシティーユニット:1
- 最大キャパシティーユニット:10
- ターゲット使用率:70%
発生したエラーについて
Failed to set write capacity units to 1. Reason: Failed updating table: Subscriber limit exceeded: Provisioned throughput decreases are limited within a given UTC day. After the first 4 decreases, each subsequent decrease in the same UTC day can be performed at most once every 3600 seconds. Number of decreases today: 4. Last decrease at Thursday, January 23, 2025 at 8:51:30 AM Coordinated Universal Time. Next decrease can be made at Thursday, January 23, 2025 at 9:51:30 AM Coordinated Universal Time (Service: AmazonDynamoDBv2; Status Code: 400; Error Code: LimitExceededException; Request ID: DVJ5M62V9KLC5MVD3TV49TT4SFVV4KQNSO5AEMVJF66Q9ASUAAJG; Proxy: null) (Service: null; Status Code: 400; Error Code: LimitExceededException; Request ID: null; Proxy: null).
エラーを見ると書き込みキャパシティー1を設定できなかったとあります。
理由は1日あたりのキャパシティー数減少実行の制限に抵触して、Auto Scalingに失敗したようですね。上記エラーには最初の1時間は4回、それ以降は1時間に1回といった記載があります。
ここで公式ドキュメントを見てみましょう。
公式ドキュメントより引用
プロビジョニングされたスループットの増加
ReadCapacityUnitsまたはWriteCapacityUnitsオペレーションを使用して、必要な回数だけ AWS Management Console またはUpdateTableを増やすことができます。1 回の呼び出しで、テーブル、そのテーブルの任意のグローバルセカンダリインデックス、またはこれらの任意の組み合わせに対して、プロビジョニングされるスループットを増やすことができます。新しい設定は、UpdateTableオペレーションが完了するまでは有効になりません。プロビジョニングされたキャパシティーを追加する場合、アカウントごとのクォータを超えることはできません。また、DynamoDB では、プロビジョニングされたキャパシティーを急速に増やすことはできません。これらの制限に達しない限り、テーブルのプロビジョニング容量を必要なだけ増やすことができます アカウントごとのクォータの詳細については、前述の「スループットのデフォルトクォータ」セクションを参照してください。
プロビジョニングされたスループットの減少
UpdateTableオペレーションのすべてのテーブルとグローバルセカンダリインデックスでは、ReadCapacityUnitsかWriteCapacityUnits(またはその両方) を減らすことができます。新しい設定は、UpdateTableオペレーションが完了するまでは有効になりません。1 日あたりの DynamoDB テーブルで実行できるプロビジョンドキャパシティーの減少数には、デフォルトのクォータがあります。日付は、協定世界時 (UTC) に従って定義されます。特定の日に、その日に他の減少をまだ実行していない限り、1 時間以内に最大 4 回の減少を実行することから始めることができます。その後、1 時間あたり 1 回追加で減少を実行できます (60 分に 1 回)。これにより、1 日の最大減少回数は 27 回になります。
増加に際しては、アカウント単位のクォータを超過できない、急速にキャパシティーを増加できない限りは増加できると記載がありますが、減少の場合はより厳格な条件がありエラーメッセージであったように最初の1時間は4回、それ以降は1時間に1回追加で減少を実行できるようになります。
つまり何が起きたのか?
では、今回の事象の原因は何だったのでしょうか。エラーメッセージが減少の実行回数超過となっているので、減少が頻繁に行われていることが読み取れます。
また設定していた最小キャパシティー数が1だったこともあり、少しの負荷でAuto Scalingが発生して、キャパシティー数が増加、負荷が落ち着いたタイミングでキャパシティー数の減少を短期間で頻繁に繰り返していたため上記エラーが発生した可能性があります。
上記仮説が妥当かどうかテーブルを作って環境を再現して、その上で対応方法について考えていきたいと思います。
環境構築
負荷をかけて今回の事象を再現するDynamoDBのテーブルを作成します。
テーブル作成
-
DynamoDBのコンソール画面から
テーブルの作成ボタンを押下

-
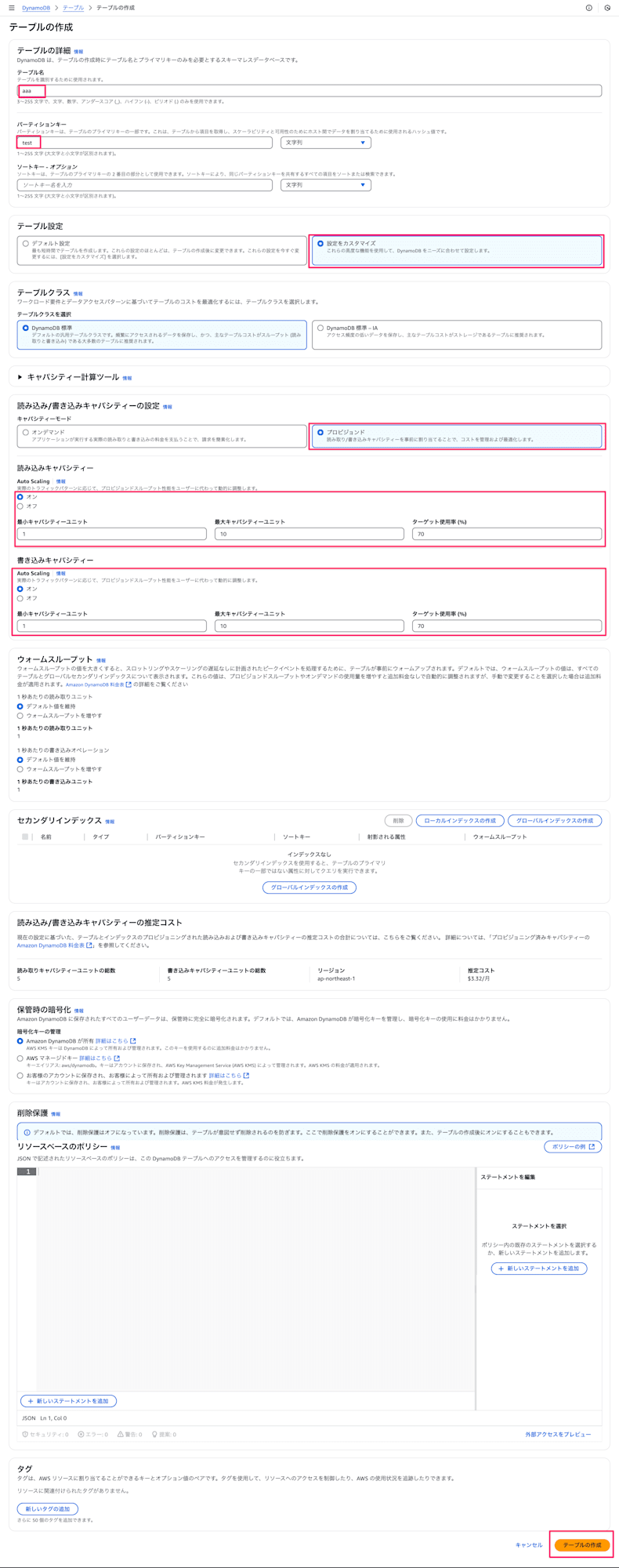
下記情報を入力して、
テーブルの作成ボタンを押下- テーブル名:
aaa(任意のテーブル名) - パーティションキー:
test(任意のキー名) - テーブル設定:
設定をカスタマイズ - キャパシティーモード:
プロビジョンド - Auto Scaling:
ON(読み込み・書き込み両方とも)- 最小キャパシティーユニット:
1 - 最大キャパシティーユニット:
10 - ターゲット使用率:
70
- 最小キャパシティーユニット:
- テーブル名:
-
ボタン押下後、下記バナーが表示されていればOKです!

検証
今回はCloudShellで下記Pythonスクリプトを使って負荷をかけていきます。
スクリプト全体
import boto3
import time
from concurrent.futures import ThreadPoolExecutor
import random
import string
# DynamoDB クライアントの設定
dynamodb = boto3.client('dynamodb')
# 任意のテーブル名を指定
table_name = 'aaa'
# ランダムな文字列を生成する関数
def generate_random_string(length=10):
return ''.join(random.choices(string.ascii_letters + string.digits, k=length))
# 1つのアイテムを書き込む関数
def put_item():
try:
response = dynamodb.put_item(
TableName=table_name,
Item={
'test': {'S': generate_random_string()},
'timestamp': {'N': str(int(time.time()))},
'data': {'S': generate_random_string(50)}
}
)
return True
except Exception as e:
print(f"Error: {e}")
return False
# メイン処理
def main():
# 同時実行数
concurrent_requests = 10
# 総リクエスト数
total_requests = 1000
success_count = 0
start_time = time.time()
with ThreadPoolExecutor(max_workers=concurrent_requests) as executor:
results = list(executor.map(lambda _: put_item(), range(total_requests)))
success_count = sum(results)
end_time = time.time()
duration = end_time - start_time
if __name__ == "__main__":
main()
上記スクリプトのファイル名をput_data_to_dynamodb.pyとしてCloudShell上で作成、もしくはローカルで作成してコピーして、下記コマンドで実行します。
python put_data_to_dynamodb.py
実行が完了したらAutoScalingが実行されているかコンソール上で確認してみます。
下記のようにAuto Scaling アクティビティにログが表示されていればOKです!

最小書き込みキャパシティーを1としていたので、2へスケールしていますね。
元のキャパシティーに戻すよう負荷をかけずに放置します。しばらく待つと下記のように、キャパシティー数が減少されます。

これで負荷増加→Auto Scalingによるキャパシティー数増加→負荷が落ち着いたためキャパシティー数が減少の一連のサイクルを再現しました。今度は短期間でこのサイクルを繰り返して減少の上限エラー発生を狙います。
人力で何度か頑張ってやっていたところ、始めてから1時間半経過ぐらいの5回目のサイクルでの減少時に同様のエラーが発生しました。
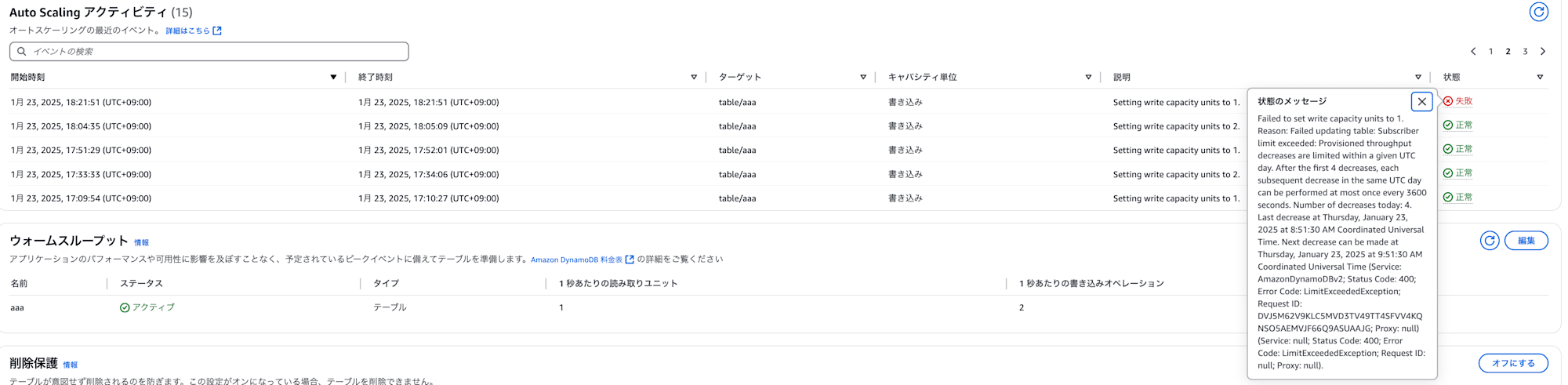
その後にもキャパシティー数を減少させようと何度かエラーが発生していて、最終的に時間経過とともに減少回数が1回追加されたタイミングで元のキャパシティー数に戻りました。

最初に立てた仮説通り短期間で頻繁にAuto Scalingを繰り返して、キャパシティー数減少実行の上限に引っかかるというのは現実的にあり得そうだとわかりました。
対応案
それでは、どのように対応するのが良いか考えていきましょう。下記対応を検討していきます。
- 最小キャパシティー数を1から増やす
- Auto Scalingのターゲット使用率を見直す
- キャパシティーモードを
プロビジョンド→オンデマンドへの変更
最小キャパシティ数・ターゲット使用率の見直し
現状、最小キャパシティー数の設定値が低いため想定以上のリクエストが発生しやすくAuto Scalingが多発しているのかと思います。そのため現状どれだけのキャパシティー数が使用されているのか確認していく必要があるかと思います。
方法としては下記があるかと思います。
describe-scaling-activitiesAPIを使用してAuto Scalingログを取得する- CloudWatch上でキャパシティー数の推移を確認する
describe-scaling-activitiesAPIを使用してAuto Scalingログを取得する
describe-scaling-activitiesAPIを使用して、DynamoDBの直近6週間のAutoScalingログを取得することができます。サンプルとしては下記になります。
aws application-autoscaling describe-scaling-activities --service-namespace dynamodb --resource-id "table/aaa" --max-items 500 > scaling_history.json
引数としては下記を設定します。
- --service-namespace:
dynamodb(固定) - --resource-id:
table/任意のテーブル名 - --max-items:
取得したい上限数
実行結果は下記形式で返却されるので、直近でどれだけAuto Scalingが発生しているかの頻度や変化などをテキストベースで確認することができます。ただ具体的に時系列で見たいとなった際は後者のCloudWatch上でキャパシティー数の推移を視覚的に確認した方がわかりやすいかと思います。
{
"ScalingActivities": [
{
"ActivityId": "30bbbcde-9221-4cd3-bfbe-9ac5c1cf6111",
"ServiceNamespace": "dynamodb",
"ResourceId": "table/aaa",
"ScalableDimension": "dynamodb:table:WriteCapacityUnits",
"Description": "Setting write capacity units to 1.",
"Cause": "monitor alarm TargetTracking-table/aaa-AlarmLow-9a2fe981-c6f0-4ca7-a0a6-6be00614a99f in state ALARM triggered policy $aaa-scaling-policy",
"StartTime": "2025-01-23T07:19:41.367000+00:00",
"EndTime": "2025-01-23T07:20:17.963000+00:00",
"StatusCode": "Successful",
"StatusMessage": "Successfully set write capacity units to 1. Change successfully fulfilled by dynamodb."
},
{
"ActivityId": "655b62fe-9101-4918-adfe-ae778f053e5f",
"ServiceNamespace": "dynamodb",
"ResourceId": "table/aaa",
"ScalableDimension": "dynamodb:table:WriteCapacityUnits",
"Description": "Setting write capacity units to 2.",
"Cause": "monitor alarm TargetTracking-table/aaa-AlarmHigh-24cc93ad-a15e-4da0-aa4d-ee9ecde858cb in state ALARM triggered policy $aaa-scaling-policy",
"StartTime": "2025-01-23T07:00:53.424000+00:00",
"EndTime": "2025-01-23T07:01:24.878000+00:00",
"StatusCode": "Successful",
"StatusMessage": "Successfully set write capacity units to 2. Change successfully fulfilled by dynamodb."
}
]
}
CloudWatch上でキャパシティー数の推移を確認する
ConsumedWriteCapacityUnitsやConsumedReadCapacityUnits,ProvisionedWriteCapacityUnits,
ProvisionedReadCapacityUnitsメトリクスを参考に現状どれだけのキャパシティー数が使用されているのか確認して最小キャパシティー数の検討を行うのがいいかとも思います。
各種メトリクスの値はDynamo DBのコンソール画面からもCloudWatchに遷移して確認できます。
Dynamo DBのコンソール
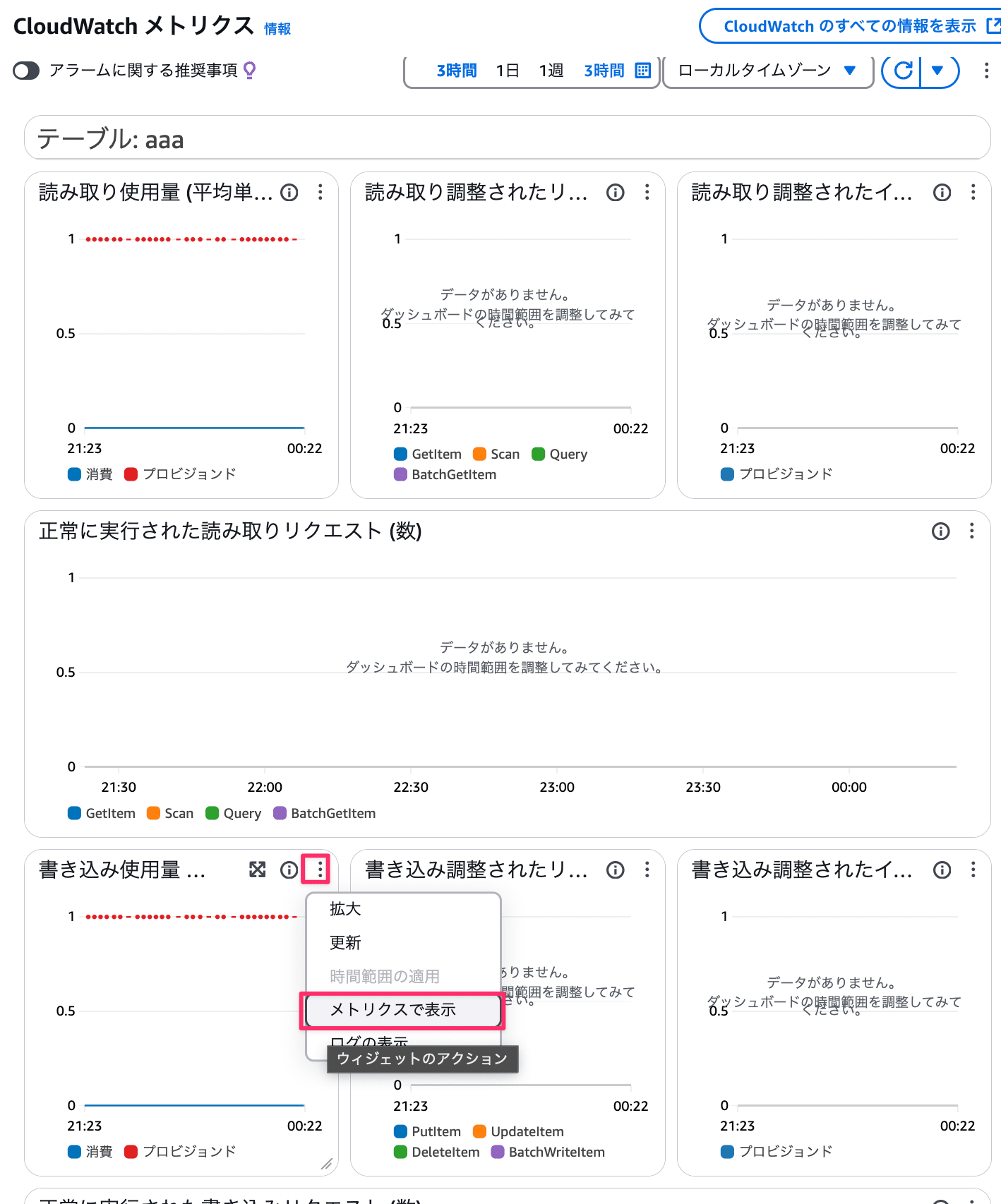
書き込み使用量の例
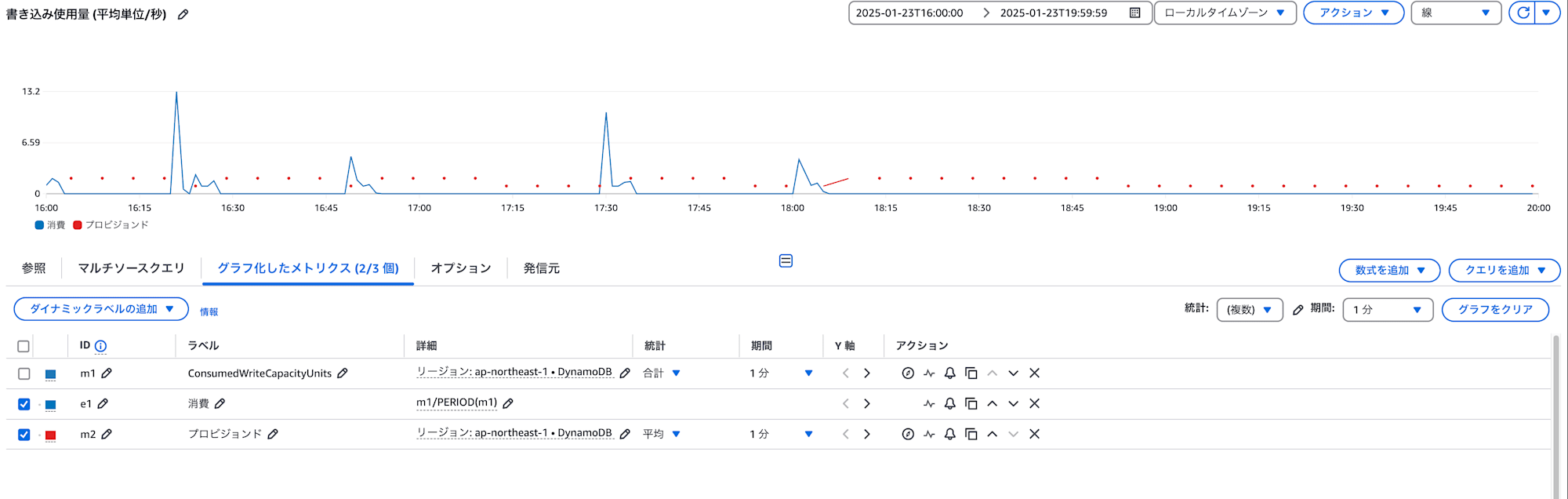
この2つの方法で現状のキャパシティー数使用状況を確認して、より適切な最小キャパシティー数やAutoScalingのターゲット使用率の見直しを図ります。
補足:各メトリクスの説明
- ConsumedWriteCapacityUnits: 実際に消費された書き込みキャパシティーユニット
- ProvisionedWriteCapacityUnits: プロビジョニングされた書き込みキャパシティーユニット
- ConsumedReadCapacityUnits: 実際に消費された読み取りキャパシティーユニット
- ProvisionedReadCapacityUnits: プロビジョニングされた読み取りキーャパシティユニット
キャパシティーモードをプロビジョンド→オンデマンドへの変更
上記案でも全く改善ができないもしくは使用量が予測できない場合はキャパシティーモードをオンデマンドにするのも手かと思います。
プロビジョンドの目的は予測可能なワークロードに対して、事前に必要なキャパシティを確保しコストを最適化することです。一方で予測が難しく、Auto Scalingの制限に頻繁に抵触するような状況では、オンデマンドモードの方が適している可能性があります。
オンデマンドモードでは、実際のリクエスト量に応じて自動的にスケーリングが行われ、明示的なキャパシティー設定や Auto Scaling の設定は不要になります。ただし、プロビジョンドと比較してコストが高くなる可能性があることは留意する必要があります。
Auto Scalingの失敗による弊害
一方で今回のエラーのように、キャパシティーモードがプロビジョンドかつAuto Scalingでキャパシティー数が元に戻すための減少が実行できない場合どんな弊害があるのでしょうか。
増加したキャパシティー数を元に戻せないエラーなので、アプリケーション側には大きな影響はないかと思います。ただ下記コストや運用面には考慮する必要があるかと思います。
- 必要以上に高いキャパシティーを維持することになるため、余分なコストが発生
- ただキャパシティーモードを
オンデマンドにしてエラーを解消しても、コストの増加はあり得るので、プロビジョンドとオンデマンドのコスト比較を慎重に行う必要がある
- ただキャパシティーモードを
- AutoScalingの失敗エラーをアラートのトリガーとしている場合は、アラートが頻発することによる「アラート疲れ」が発生し、運用コストが増加
- 大量のAuto Scaling失敗アラートの中に、より重要な他のアラートが埋もれてしまう
- 運用チームが「またAuto Scalingのアラートか」と慣れてしまい、本当に対応が必要なアラートを見逃す可能性
おわりに
DynamoDBのAuto Scaling失敗は、主にスケールダウン時の制限に起因して発生します。直接的なアプリケーション影響は限定的ですが、運用コストやモニタリングの質に影響を与える可能性があります。
対策は以下を検討する必要があります。
- 現状のキャパシティー使用量をログおよびCloudWatchから把握し、適切な最小キャパシティー設定およびターゲット使用率の見直し
- 負荷予測が全くできない場合はキャパシティーモードを
プロビジョンド→オンデマンドへの変更を検討
正解はこれと言ってないかとは思いますが、上記を検討しつつより良い設計への一歩となりましたら幸いです。
最後までご覧いただきありがとうございました!!









